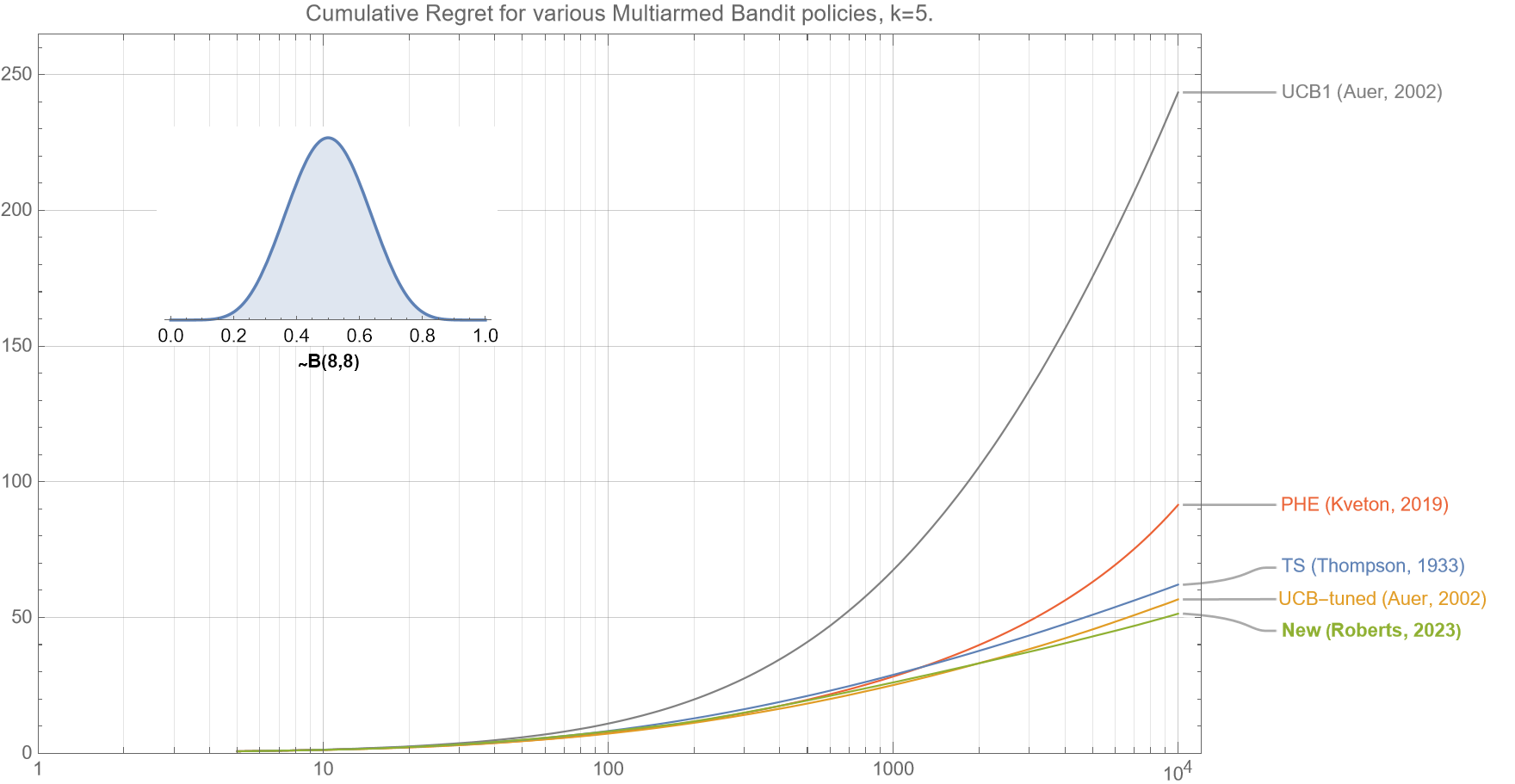
I propose a new algorithm for multi-armed bandits that is fully deterministic, as fast and simple to implement as UCB1, and yet, for a very broad range of practical circumstances empirically outperforms many of the existing industry standard Bernoulli multi-armed bandit policies, including Thompson Sampling and UCB1 and UCB-tuned.
Continue reading “Improving on the UCB1 multi-armed bandit algorithm”