I describe a probabilistic alternative to fractional factorial design based on the Sobol’ low discrepancy quasirandom sequence. This method is robust to aliasing (confounders), is often simpler to implement than traditional fractional factorial sample designs, and produces more accurate results than simple random sampling.
Introduction
Consider the scenario that you are managing a complex system with many variables and you need to know estimate the main effect size of each the variables. What do you do?
In the simplest case where you have say $k=4$ variables: $x_1,x_2,x_3$, and $x_4$, each of which can only take one of two options, the classic scientific approach would be to run a full factorial experiment consisting of $2^4=16$ separate experiments each corresponding to one of the 32 distinct possibilities. That is:
\begin{array}{|c|cccc|c|} \hline
i & x_1 & x_2 & x_3 & x_4 & Y_i \\ \hline
1 & 0 & 0 & 0 & 0 & Y_1\\ \hline
2 & 0 & 0 & 0 & 1 & Y_2\\ \hline
3 & 0 & 0 & 1 & 0 & Y_3\\ \hline
4 & 0 & 0 & 1 & 1 & Y_4\\ \hline
5 & 0 & 1 & 0 & 0 & Y_5\\ \hline
6 & 0 & 1 & 0 & 1 & Y_6\\ \hline
7 & 0 & 1 & 1 & 0 & Y_7\\ \hline
8 & 0 & 1 & 1 & 1 & Y_8\\ \hline
9 & 1 & 0 & 0 & 0 & Y_9\\ \hline
10 & 1 & 0 & 0 & 1 & Y_{10}\\ \hline
11 & 1 & 0 & 1 & 0 & Y_{11}\\ \hline
12 & 1 & 0 & 1 & 1 & Y_{12}\\ \hline
13 & 1 & 1 & 0 & 0 & Y_{13}\\ \hline
14 & 1 & 1 & 0 & 1 & Y_{14}\\ \hline
15 & 1 & 1 & 1 & 0 & Y_{15}\\ \hline
16 & 1 & 1 & 1 & 1 & Y_{16}\\ \hline
\end{array}
From this, one can estimate the main average effect (AES) size for each of the variables. For example,
$$\textrm{AES} (x_1) = \textrm{avg} \{ Y_9,Y_{10},Y_{11},Y_{12},Y_{13},Y_{14},Y_{15},Y_{16} \} – \textrm{avg} \{ Y_1,Y_2,Y_3,Y_4,Y_5,Y_6,Y_7,Y_8 \}. $$
Fractional Factorial Sample design
The obvious major problem with this complete enumeration approach is that for $k$ variables, each of which can take $\lambda$ levels, requires $N=\lambda^k$ trials, which very quickly explodes. In such cases it is common to consider fractional factorial designs using orthogonal arrays. A typical fractional design for the above scenario would be:
\begin{array}{|c|cccc|c|} \hline
i & x_1 & x_2 & x_3 & x_4 & Y_i \\ \hline
1 & 0 & 0 & 0 & 0 & Y_1\\ \hline
2 & 0 & 0 & 0 & 1 & Y_2\\ \hline
3 & 0 & 1 & 1 & 0 & Y_3\\ \hline
4 & 0 & 1 & 1 & 1 & Y_4\\ \hline
5 & 1 & 0 & 1 & 0 & Y_5\\ \hline
6 & 1 & 0 & 1 & 1 & Y_6\\ \hline
7 & 1 & 1 & 0 & 0 & Y_7\\ \hline
8 &1 & 1 & 0 & 1 & Y_8\\ \hline
\end{array}
Orthogonal arrays possess the characteristic that for any combination of $1 \leq t \leq k$ columns, all ordered $t$-tuples formed by taking the entries in these columns, appear with equal frequency. In this example, the fractional factorial design only 8 trials rather than 16. In many real-life situations, with many more variables and/or levels, the associated reduction is even greater. Taguchi was one of the first people to use orthogonal arrays in industrial testing applications.
Looking at the above-design, one may be tempted to immediately conclude that:
$$\textrm{AES} (x_1) = \textrm{avg} \{ Y_5,Y_6,Y_7,Y_8 \} – \textrm{avg} \{ Y_1,Y_2,Y_3,Y_4 \} $$
However, the subtle but major problem with this approach is that the combinations of $\{x_2,x_3,x_4\}$ in each of these expressions is different. For $x_1=0$ we have $\{000,001,110,111\}$, whereas for $x_1=1$, they are $\{ 010,011,100,101\}$.
If there is a possibility that some variables are not independent, you need to adjust for this difference by taking into account confounding higher-order effects. That is, the 2-way and 3-way interactions between the variables. However, even if you follow through on this approach you will soon discover that it is still not possible to fully separate all the main effects from confounders. This problem is intrinsic to fractional sample designs.
Aliasing, also known as confounding, occurs in fractional factorial designs because the design does not include all of the combinations of factor levels. Terms that are confounded are also said to be aliased.
That is, in situations where there may be interactions (that is confounders), fractional factorial designs can be quite challenging and much of the work and skill in fractional factorial design using orthogonal arrays is focused on minimizing (or hiding) the effects of this aliasing.
The most common approach for sample design that is intrinsically protected from confounders is simple randomised sampling. For each trial, simply select a random value for each variable. In this manner, the statistical distribution of combinations for $\{x_2,x_3,x_4 \}$ will be the same for $x_1=0$ compared to $x_1=1$.
Random Sampling has another very nice property that simple full factorial design does not have: namely it is progressive. In the full factorial example above, if the experiment has to cease after just 8 trials due to running out of time or money, then it is clear that it is not possible to obtain an estimate for the main effect of $x_1$.
Random sampling does not have an intrinsic block length, and so it can cease or proceed for an arbitrary number of trials, with estimates getting progressively more accurate as trials increase.
The disadvantage of simple random sampling is that sometimes you may get the same combination repeated before all possible combinations have been implemented. Furthermore, ‘just by chance’, you may run an large number of trials with a particular variable combination is selected. ( Of course, the law of large numbers dictates that in the limit as $N \rightarrow \infty$, the estimates will converge as if a full factorial design was implemented.)
This possible repetition and/or omission of particular variable combinations for finite N, is the main reason why the confidence intervals for the estimates only converge at a rate of $1/ \sqrt{N}$.
Quasirandom Sample Design
Of course, readers of this blog will at once think that there is another possibility: Instead of using simple random sampling, is it possible to sample based on a low discrepancy quasirandom sequences?
The answer is yes! You certainly can.
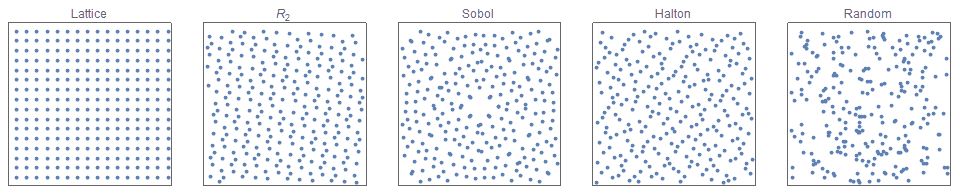
Quasirandom sequences produce samples that are more random than grid-based sampling, but more regular than uniform random sampling. Wikipedia offers a gentle introduction to quasirandom sequences, and my previous blog “The unreasonable effectiveness of Quasirandom sequences” offers a more in-depth look at them including introducing a new sequence $R_d$ that has many beautiful properties.
In theory, you can use any of the well known low discrepancy sequences, but in practice for this binary particular application, the Sobol’ sequence produces consistently excellent results. (For sample designs where $\lambda \neq 2$, the $R_d$ sequence is often equally effective, and sometimes significantly better.
As a first step, I show how to replicate the above sample design using the Sobol’ sequence.
Consider a 5-dimensional Sobol sequence.
$$T^{(i)} = \{\mathbf{x}^{i} \}= \{x^i_1,x^i_2,x^i_3,x^i_4,x^i_5\}$$
where $i = 0,1,2,\ldots$ and $0\leq x^i_j <1$ for all $i,j$.
Convert the numbers into integers via the basic function
$$f(z) = \textrm{Floor}( k z )$$ where $k$ is the number of different values that the variable can take. In this simple case, k=2.
The first 8 trials are then:
\begin{array}{|c|cccc|cccc|c|} \hline
i & z_1 & z_2 & z_3 & z_4 & x_1 & x_2 & x_3 & x_4 & Y_i \\ \hline
1 & 0.79 & 0.89 & 0.58 & 0.63 & 1 & 1 & 1 & 1 & Y_1\\ \hline
2 & 0.29 & 0.39 & 0.83 & 0.38 &0 & 0 & 1 & 0 & Y_2\\ \hline
3 & 0.04 & 0.64 & 0.33 & 0.88 & 0 & 1 & 0 & 1 & Y_3\\ \hline
4 & 0.54 & 0.14 & 0.46 & 0.25 & 1 & 0 &0 & 0 & Y_4\\ \hline
5 & 0.41 & 0.77 & 0.96 & 0.75 & 0 & 1 & 1 & 1 & Y_5\\ \hline
6 & 0.91 & 0.27 & 0.71 & 0.09 &1 & 0 & 1 & 0 & Y_6\\ \hline
7 & 0.66 & 0.52 & 0.21 & 0.50 & 1 & 1 & 0 & 1 & Y_7\\ \hline
8 & 0.16 & 0.02 & 0.14 & 0.44 & 0 & 0 & 0 & 0 & Y_8\\ \hline
…
\end{array}
Recall that this is an open-ended sequence, where we have simply shown the first 8 trials for the sake of brevity.
The most beautiful characteristic of using a quasirandom sequence is that in the above sample design, each variable is selected 4 times. Thus, the estimated main effect size of $x_1$ is:
$$\textrm{AES} (x_1) = \textrm{avg} \{ Y_1,Y_4,Y_6,Y_7 \} – \textrm{avg} \{ Y_2,Y_3,Y_5,Y_8 \} $$
Furthermore, for both $x_1=0$ and $x_1=1$, the $\{ x_2,x_3,x_4\}$ combinations are: $\{ 010,101,111,000\}$!
To further emphasize how elegant this sample design is, we show the progressive selection frequencies of each variable and pair of variables, for the first 16 terms. (You can do the same for triplets of variables, but we don’t show it here for sake of brevity).
You can see that the frequency counts between each of the variables never differs by more than 1, and the pairwise frequency counts never differ by more than 2. Therefore, although perfect results are obtained if $N$ is a multiple of 16, you can still obtain good results for arbitrary $N$.
\begin{array}{|c|cccc|c|cccc|cccc|} \hline
i & x_1 & x_2 & x_3 & x_4 & Y_i & x_1 & x_2 & x_3 & x_4 & x_1 x_2 & x_1 x_3 & x_1 x_4 & x_2 x_3 & x_2 x_4 & x_3 x_4 & \\ \hline
1 & 1 & 1 & 1 & 1 & Y_1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 &1 \\ \hline
2 & 0 & 0 & 1 & 0 & Y_2& 1 & 1 & 2 & 1 & 1 & 1 & 1 & 1 & 1 &1 \\ \hline
3 & 0 & 1 & 0 & 1 & Y_3 & 1 & 2 & 2 & 2 & 1 & 1 & 1 & 1 & 2 &1 \\ \hline
4 & 1 & 0 & 0 & 0 & Y_4 & 2 & 2 & 2 & 2 & 1 & 1 & 1 & 1 & 2 &1 \\ \hline
5 & 0 & 1 & 1 & 1 & Y_5 & 2 & 3 & 3 & 3 & 1 & 1 & 1 & 2 & 3 &2 \\ \hline
6 & 1 & 0 & 1 & 0 & Y_6 & 3 & 3 & 4 & 3 & 1 & 2 & 1 & 2 & 3 &2 \\ \hline
7 & 1 & 1 & 0 & 1 & Y_7 & 4 & 4 & 4 & 4 & 2 & 2 & 2 & 2 & 4 &2 \\ \hline
8 &0 & 0 & 0 & 0 & Y_8 & 4 & 4 & 4 & 4 & 2 & 2 & 2 & 2 & 4 &2 \\ \hline
9 &1 & 0 & 1 & 1 & Y_9 & 5 & 4 & 5 & 5 & 2 & 3 & 3 & 2 & 4 &3 \\ \hline
10 &0 & 1 & 1 & 0 & Y_{10} & 5 & 5 &6 &5 & 2 & 3 & 3 & 3 &4 &3 \\ \hline
11 &0 & 0 & 0 & 1 & Y_{11} & 5 & 5 & 6 &6 & 2 & 3 & 3 & 3 &4 &3 \\ \hline
12 &1 & 1 & 0 & 0 & Y_{12} & 6 & 6 & 6 &6 & 3 & 3 & 3 & 3 &4 &3 \\ \hline
13 &0 & 0 & 1 & 1 & Y_{13} & 6 & 6 & 7 & 7 & 3 & 3 & 3 & 3 &4 &4 \\ \hline
14 &1 & 1 & 1 & 0 & Y_{14} & 7 & 7 & 8 & 7 & 4 & 4 & 3 & 4 & 4 &4 \\ \hline
15 &1 & 0 & 0 & 1 & Y_{15} & 8 & 7 & 8 & 8 & 4 & 4 & 4 & 4 & 4 &4 \\ \hline
16 &0 & 1 & 0 & 0 & Y_{16} & 8 & 8 & 8 & 8 & 4 & 4 & 4 & 4 & 4 &4 \\ \hline
…
\end{array}
If you look closely you can see a hidden (inverse) Gray code in there. For each trial, each (binary) combination typically has one digit in common with the previous (and successive) sample. This is the complementary version of the standard Gray code where each binary number has exactly one digit different to the previous and successive terms. This is no coincidence, as the construction of the Sobol’ sequence is intimately connected with Gray codes.
Multiple levels
Traditionally, for a multivariable sample design, where each variable can take multiple levels, the construction of sample designs is quite complex and users typically refer to previously calculated tables such as these.
However, with the Sobol’ sequence, this above process can trivially extend to the more general case where each variable can have multiple values. In the following example, we have 4 variables, where $x_1$ can take 2 values; $x_2$ and $x_3$ can take 3 values, and $x_4$ can take 5 values. We simply multiply $\{z_1,z_2,z_3,z_4 \} $ by $\{2,3,3,5\}$ respectively, and then round down.
This sample design will repeat itself after 2x3x3x5 = 90 trials. Using the same $z$-values as above, the first 20 are shown below.
\begin{array}{|c|cccc|cccc|c|} \hline
i & z_1 & z_2 & z_3 & z_4 & x_1 & x_2 & x_3 & x_4 & Y_i \\ \hline
1 & 0.79 & 0.89 & 0.58 & 0.63 & 1 & 2 & 1 & 3 & Y_1\\ \hline
2 & 0.29 & 0.39 & 0.83 & 0.38 &0 & 1 & 2 & 1 & Y_2\\ \hline
3 & 0.04 & 0.64 & 0.33 & 0.88 & 0 & 1 & 1 & 4 & Y_3\\ \hline
4 & 0.54 & 0.14 & 0.46 & 0.25 & 1 & 0 &1 & 1 & Y_4\\ \hline
5 & 0.41 & 0.77 & 0.96 & 0.75 & 0 & 2 & 2 & 3 & Y_5\\ \hline
6 & 0.91 & 0.27 & 0.71 & 0.09 &1 & 0 & 2 & 0 & Y_6\\ \hline
7 & 0.66 & 0.52 & 0.21 & 0.50 & 1 & 1 & 0 & 2 & Y_7\\ \hline
8 & 0.16 & 0.02 & 0.14 & 0.44 & 0 & 0 & 0 & 2 & Y_8\\ \hline
9 & 0.64 & 0.33 & 0.64 & 0.94 & 1 & 1 & 1 & 4 & Y_9\\ \hline
10 & 0.10 & 0.83 & 0.89 & 0.19 & 0 & 2 & 2 & 0 & Y_{10}\\ \hline
11 & 0.35 & 0.08 & 0.39 & 0.69 & 0 & 0 & 1 & 3 & Y_{11}\\ \hline
12 & 0.85 & 0.58 & 0.27 & 0.07 & 1 & 1 & 0 & 0 & Y_{12}\\ \hline
13 & 0.22 & 0.46 & 0.77 & 0.57 & 0 & 1 & 2 & 2 & Y_{13}\\ \hline
14 & 0.72 & 0.96 & 0.52 & 0.32 & 1 & 2 & 1 & 1 & Y_{14}\\ \hline
15 & 0.97 & 0.21 & 0.02 & 0.82 & 1 & 0 & 0 & 4 & Y_{15}\\ \hline
16 & 0.47 & 0.71 & 0.03 & 0.47 & 0 & 2 & 0 & 2 & Y_{16}\\ \hline
17 & 0.98 & 0.82 & 0.53 & 0.97 & 1 & 2 & 1 & 4 & Y_{17}\\ \hline
18 & 0.148 & 0.32 & 0.78 & 0.22 & 0 & 0 & 2 & 1 & Y_{18}\\ \hline
19 & 0.23 & 0.57 & 0.28 & 0.72 & 0 & 0 & 0 & 2 & Y_{19}\\ \hline
20 & 0.73 & 0.07 & 0.40 & 0.09 & 0 & 0 & 0 & 2 & Y_{20}\\ \hline
…
\end{array}
Summary
The low discrepancy Sobol sequence can be used to construct a sequence of subsets such that the cumulative frequency of all possible subsets of variables is very evenly distributed. This sample design method is ios robust to aliasing, is often much simpler to implement than traditional fractional factorial sample designs, and produces more accurate results than simple random sampling.
My name is Martin Roberts. I have a PhD in theoretical physics. I love maths and computing. I’m open to new opportunities – consulting, contract or full-time – so let’s have a chat on how we can work together!
Come follow me on Twitter: @TechSparx!
My other contact details can be found here.
[mc4wp_form id=”1021″]
Other Posts you might like:
Hi, Thanks for the interesting post! I was curious if you have ever compared random sampling with another pseudo-random sampling method called Latin Hypercube Sampling.
Hi Sarah,
Thanks for your comment.
Yes. Latin hypercube sampling (LHS) is very useful. Techniques such as LHS are very good if you know your sample size in advance, and also that the number of dimensions is relatively low (say less than 10). The restriction to low dimensions is because if you are sampling n points per dimension, than you need total sample size of n^D.
Actually, one of my other posts: “A new method to construct isotropic blue noise with uniform projections”
is a special and (I claim) a better version of the general latin hypercube sampling, which you might like to read.
In contrast, quasirandom sequences are excellent when Sample Size is not known in advance and/or the dimensions are quite high.
If the number of dimensions is very high (say over 100) than generally Simple Random Sampling is the best approach.
Hope that helps!
Martin