In this brief post, I describes various methods to estimate uncertainty levels associated with numerical approximations of integrals based on quasirandom Monte Carlo (QMC) methods.
Note
This is a minor follow-up post to the feature article: “The unreasonable effectiveness of quasirandom sequences.”
Topics Covered
- Accuracy of quasirandom monte carlo methods compared to conventional MC methods
- Visualizing uncertainty
- rQMC: Estimating uncertainty via bootstrapping
- Estimating uncertainty via parameterisation
- Estimating uncertainty via cumulative sets
- QMC integration in higher dimensions
Quasirandom Monte Carlo methods for Numerical Integration
Consider the task of evaluating the definite integral
We may approximate this by:
- If the
- If the
- If the
This post considers two low discrepancy sequences: the (base 2) Van der Corput sequence and the
Further information on this newly proposed
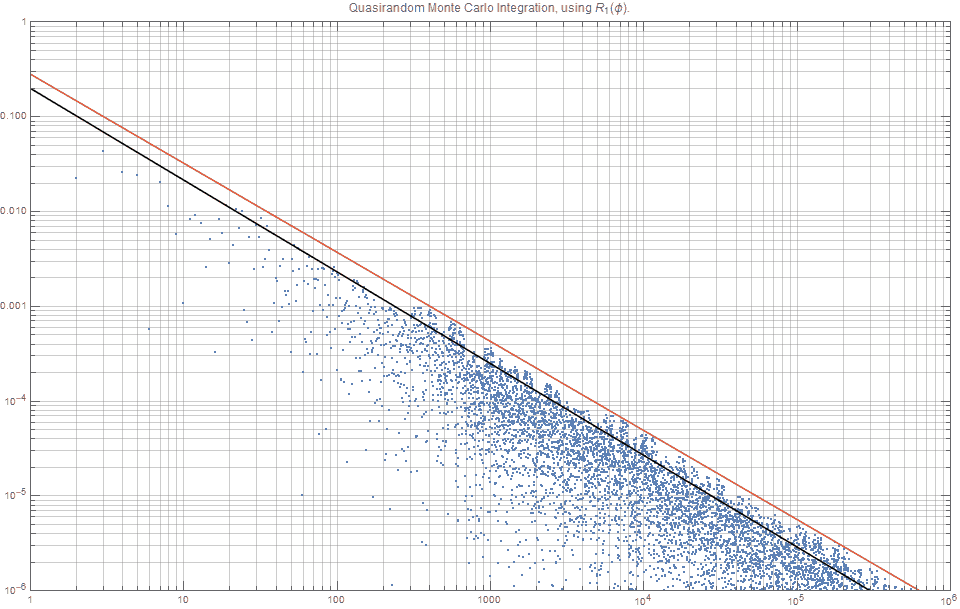
Figure 1 shows the typical error curves
Several things from figure 1 are worth noting:
- This figure illustrates the well known results that (for fixed
- The van der Corput sequence offers incredibly consistent results for integration problems – that is, extremely low variance!
- The
- A small variation in the number of sampling points /(n/), for the
This last point is the focus of this article. Namely,
For a given number of sampling points
, how can we determine the level of confidence / uncertainty associated with an approximation based on quasi-random Monte Carlo (QMC) methods?
Unlike standard random sequences that are typically used, the accuracy of a quasirandom simulations (such as those based on the Van der Corput / Halton sequences) cannot be as easily calculate or even estimated using the sample variance of the evaluations or by bootstrapping. This article explores some possible solutions to this, as well as suggesting why quasi Monte Carlo methods based on the newly proposed
Let’s initially focus on the error estimates associated with the
If one wishes to find an upper bounded approximation to the integral, then one would expect that our line would look similar to the red line, and if one wanted a expected estimate that minimized some norm (say, L1 or L2) one would expect the line to look something like the black line in figure 2. This post explores how we might calculate such lines. (Note that since figure 2 is a log-log plot, the black line is closer to the top of the blue dots, than the middle of them).
Randomized Quasi-Monte Carlo Methods: (rQMC) Basic Bootstrapping
Suppose we wish to find the uncertainty associated with an estimate based on
From figure 2 alone, one might expect that for n=1000, the error would may be be around 0.0002 (black line) but possible as high as 0.0004 (red).
A basic bootstrapping approach would be to take the set
That is, define
The two most common sampling approaches are to either:
- Create
- Create
Remembering that in practice, where
The distribution of
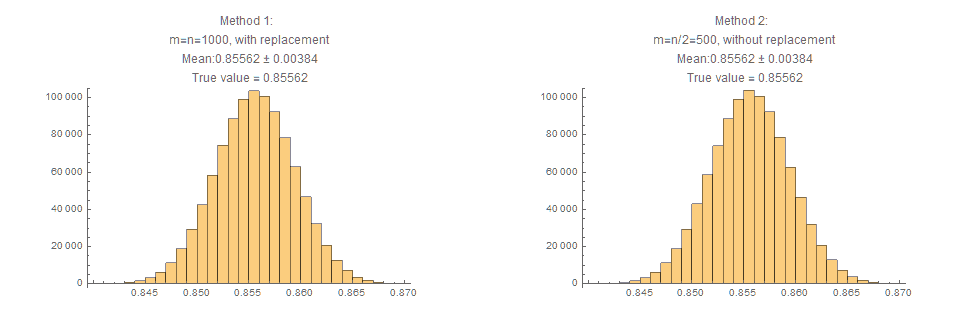
Several things to note about figure 3:
- Both methods give very virtually identical results for the estimated mean, and standard deviation .
(For those experienced with bootstrapping, this is actually to be expected, but still often worth explicitly showing.) - Both give an estimate of the mean which is within 0.00001 of the true value, and yet the uncertainty implied via the standard deviation is 0.00380.
- This 95% upper bound for the error is close to 0.008, which is considerably higher than figure 2 suggests.
That is, estimates based on these bootstrapped methods suggest a level of uncertainty much greater than the point estimates indicate in figure 2!
Based solely on this one example, this incredible precision may be attributed to just ‘good luck’ and a value slightly different to n=1000, may result in a much worse error estimate. However, a further explorations (not shown in this posts) show that the uncertainty implied by the standard deviation is consistently much greater than the actual accuracy of the estimates)
The Koksma-Hlawka inequality offers a clue as to why these estimates may not necessarily match what we expected from figure 2. The Koksma-Hlakwka inequality states that:
What this means, is that the error associated with integral approximations based on quasi random sequences can be (completely) separated into an uncertainty purely associated with the function
With this inequality, in hand, we can now think that the uncertainty analysis based on these bootstrapped methods, is more associated with the function, rather than the actual choice of
Independent Approximations: via Cranley-Patterson rotations.
Like the previous method, this method employs creating
Recall that the low discrepancy
This suggests that by calculating the integral approximants for
Figure 4 indicates that the error estimates associate with
However, more importantly we find that the standard deviation of these
This seems a lot closer to intuitive expectations than the previously variance estimates based on standard bootstrapping.
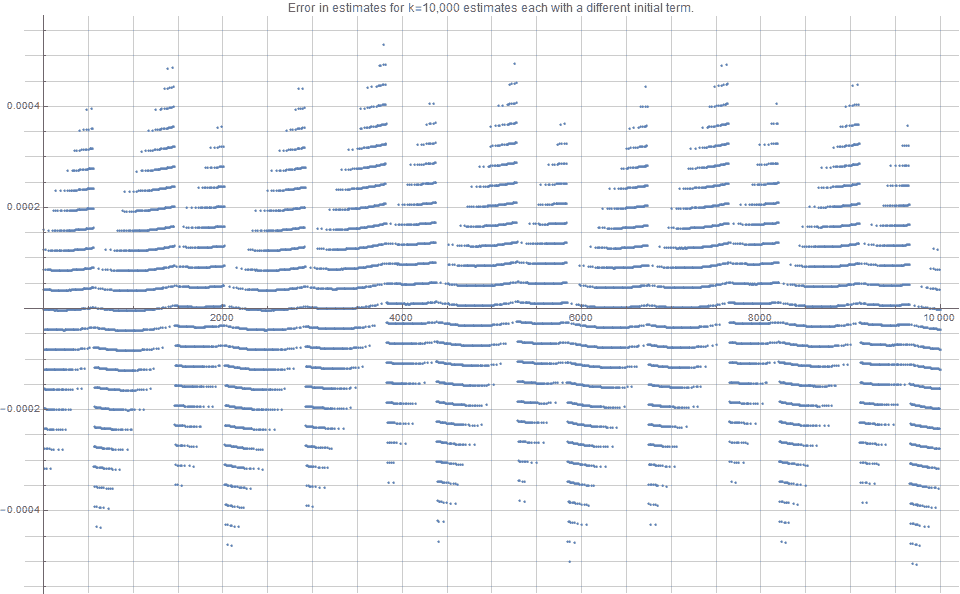
Independent Approximations – higher dimensions
The previous method works for higher dimensions, too. It just requires the selection of k different starting seeds chosen from
There is, however, also another method of finding
Suppose, d=6. Then recall that
Then another way of calculating an exact value of
This method offers
Note that this rearranging of the order of components, is fundamentally different to the scrambling techniques often used to construct higher dimensional low discrepancy sequences – where the order of the terms are rearranged.
Cumulative Approximations
If we are willing to accept a slightly lower level of independence, we can achieve an approximation to that achieved with the independent approximations method, but with far less resourcing.
Suppose we define,
Clearly,
This way, the sequence
For k=40, one can infer that the expected estimate is
- the true value 0.85562 falls within this 68% confidence interval of
- the upper bound of the 95% confidence interval suggests an upper bound error of ~ 0.00020
- this uncertainty estimate is consistent with the previous method of independent approximates.
Recall that although it is typically expensive to calculate
One can realise that if we since we are using an additive recurrence model, taking progressive / consecutive subsequences is equivalent to selecting the sequence of seed values
Furthermore, this method can work for any approximant that is based on an extensible low-discrepancy sequence. This includes the additive recurrence sequences, and Halton sequences, but not the lattices.
The simplicity, robustness, computational efficiency and generalized applicability of this final method, would suggest that with all other things being equal, this is the preferred method to estimate underlying uncertainties.
Key References
- [Snyder, 2000]
- [owen, 2008]
- [Kolenikov, 2007] (paper); [Kolenikov, 2007] (talk)
- [Taytaud, 2006]
Other Posts you might like:
- Evenly Distributing Points in a Triangle
- The Unreasonable Effectiveness of Quasirandom Sequences.
- Evenly distributing points on a sphere
- A simple method to construct isotropic quasirandom blue noise point sequences
- Going Beyond the Golden ratio