When points are placed in a canonical grid layout, they are well-separated and their projections are uniform. I present a simple canonical grid layout which offers better closest-neighbor characterisics than the two most common contemporary canonical layouts.

First published: 13rd May, 2020
Last updated : 15th May, 2020
1. Canonical Configurations
There are two very simple methods to distribute grid-based points such that the points are very nearly optimally spaced apart, whilst ensuring that the projections are exactly uniformly distributed. These are shown in figure 2a and figure 2b.
Note for both variations, there is exactly one point in every row, every column, and every block. These row and column constraints mean the projections are uniformly distributed, and the block-constraint drives the equal-spacing between neighboring points.
Due to these elegant properties, these canonical grid layouts are common in the computer graphics world. First popularised by Chiu, Shirly and Wang . And in more recent times, by Kensler and also by Jarosz. Also of interest is how van der Beek uses it in font rendering.
Their regular structure is both a blessing and a curse. It is often highly desirable to have well-separated points—especially ones which possess uniform projections. However, it is often a curse because the strong regularity causes undesirable fourier peaks and/or aliasing artefacts.
To counter this problem, it is common to scramble the rows and columns in some way in order to reduce the regularity and thus reduce the resulting artefacts. For example, see my blog post “A new method to construct isotropic blue-noise sample point sets with uniform projections“, on how to shuffle these points in a manner that results in an almost isotropic point distriobution with excellent closest neighbor separation.
However, this shuffling always comes at a cost. The point-separation statistics always deteriorate. Sometimes, only by a small amount, but nevertheless, they are no longer remain optimal. In the situations where aliasing is not an issue, it would be ideal to find a canoncial layout where the closest-neighbor statistics are as large as possible.
2. Closest Neighbor Statistics
Let us define $\delta_i$ as the distance from the $i$-th point to its closest neighbor. We adopt the convention that the edges are ‘wrapped’. That is, the grid is topologically equivalent to a torus. This is equivalent to imagining that the grid is infinitely tiled in both directions.
The three most important neighboring point statistics are: $\delta_{\rm{min}}, \delta_{\rm{max}}, \delta_{\rm{avg}} $, which naturally represent the min, max and mean of all $\delta_i$ across all $n^2$ points.
Overall, for both variants, it is clear that most of the points (all those located in an interior row or column) are well separated by a distance $\delta = \sqrt{n^2+1}/n^2$.
For the first variant shown in figure 2a, when the grid is tiled, then the top-left point (1,8) will be extremely close to the lower-right point (8,1). In this case, $\delta_i = \sqrt{2}/n^2$.
In summary, for the first variant:
$$ \sqrt{2}/n^2 \leq \delta_i \leq (\sqrt{n^2+1})/n^2 $$
For example, for $n=8$,
$$ \delta_{\rm{min}} = 1.414/64 \leq \delta_i \simeq 8.062/64 = \delta_{\rm{max}} $$
Similarly, the average distance to the closest neighbor is:
$$ \delta_{\rm{avg}}= \left(2\sqrt{2} + (n^2-2) \sqrt{n^2+1} \right) / n^4$$
Note that for all $n$, $\delta_{\rm{avg}}$ is always slightly less than $1/n$.
For example, for $n=8$, $\delta_{\rm{avg}} \simeq 7.854/64 $.
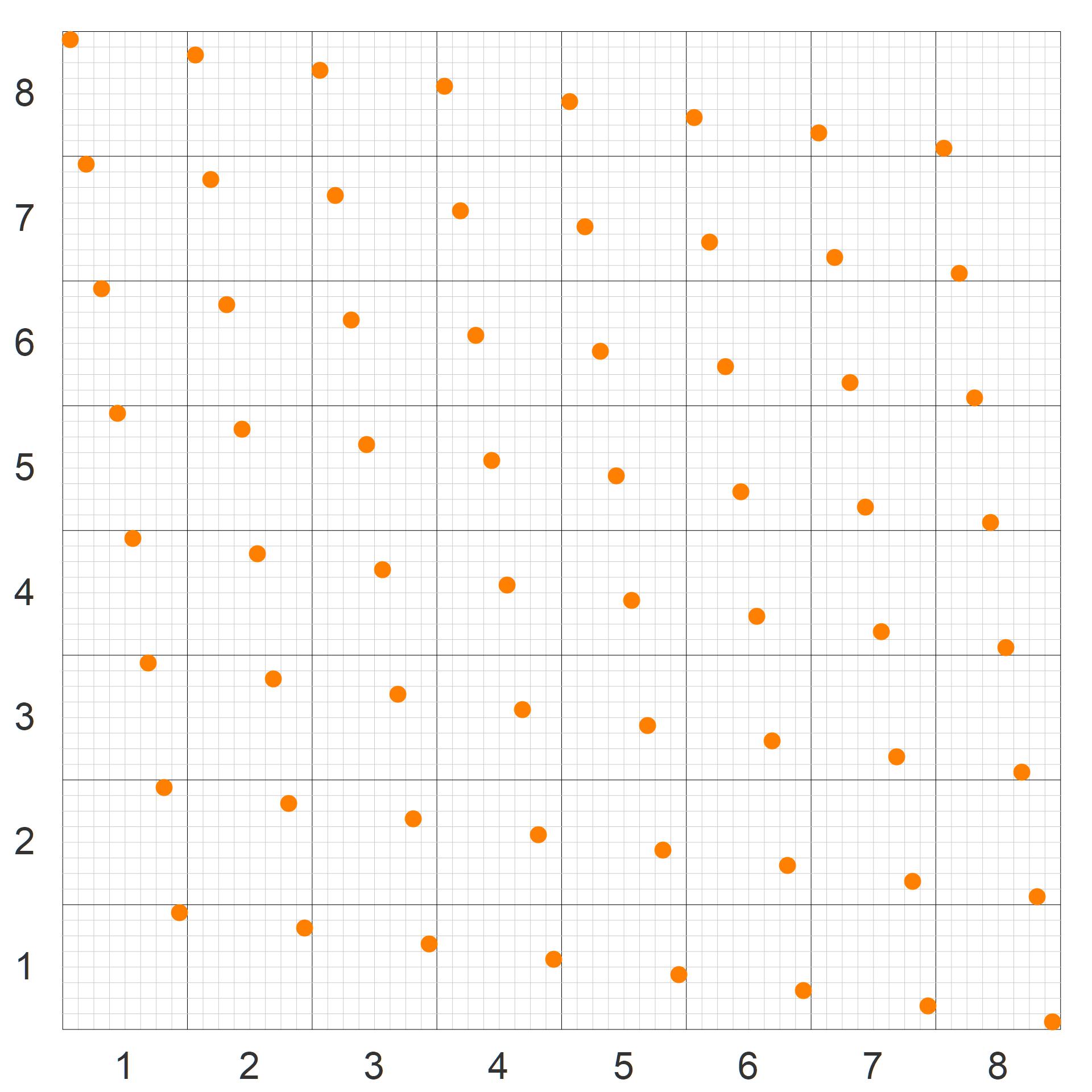
The second variant (figure 2b) often called the “rotated grid“, is notably better, as it does not have any catastrophically close points. The closest neighboring points occur at the edges. For example, the distance between points (8,8) and (1,7) is $\delta = (\sqrt{(n-1)^2+1})/n^2$.
In summary, for the second variant:
$$ (\sqrt{(n-1)^2+1} )/n^2 \leq \delta_i \leq (\sqrt{n^2+1})/n^2$$
For example, for $n=8$,
$$ \delta_{\rm{min}} = 7.071/64 \leq \delta_i \leq 8.062/64 = \delta_{\rm{max}} $$
And now, the average distance to the closest neighbor is
$$\delta_{\rm{avg}} = \left( 4(n-1) \sqrt{(n-1)^2+1} + (n-2)^2 \sqrt{n^2+1} \right) /n^4$$
This average distance is again slightly less than $1/n$.
For example, for $n=8$, $\delta_{\rm{avg}} \simeq 7.629/64 $
We note that $\delta_{\rm{min}}$ is larger (better) in the second variant than the first variant, but $\delta_{\rm{avg}} $ is smaller (worse). Thus, each variant has its strengths and weaknesses.
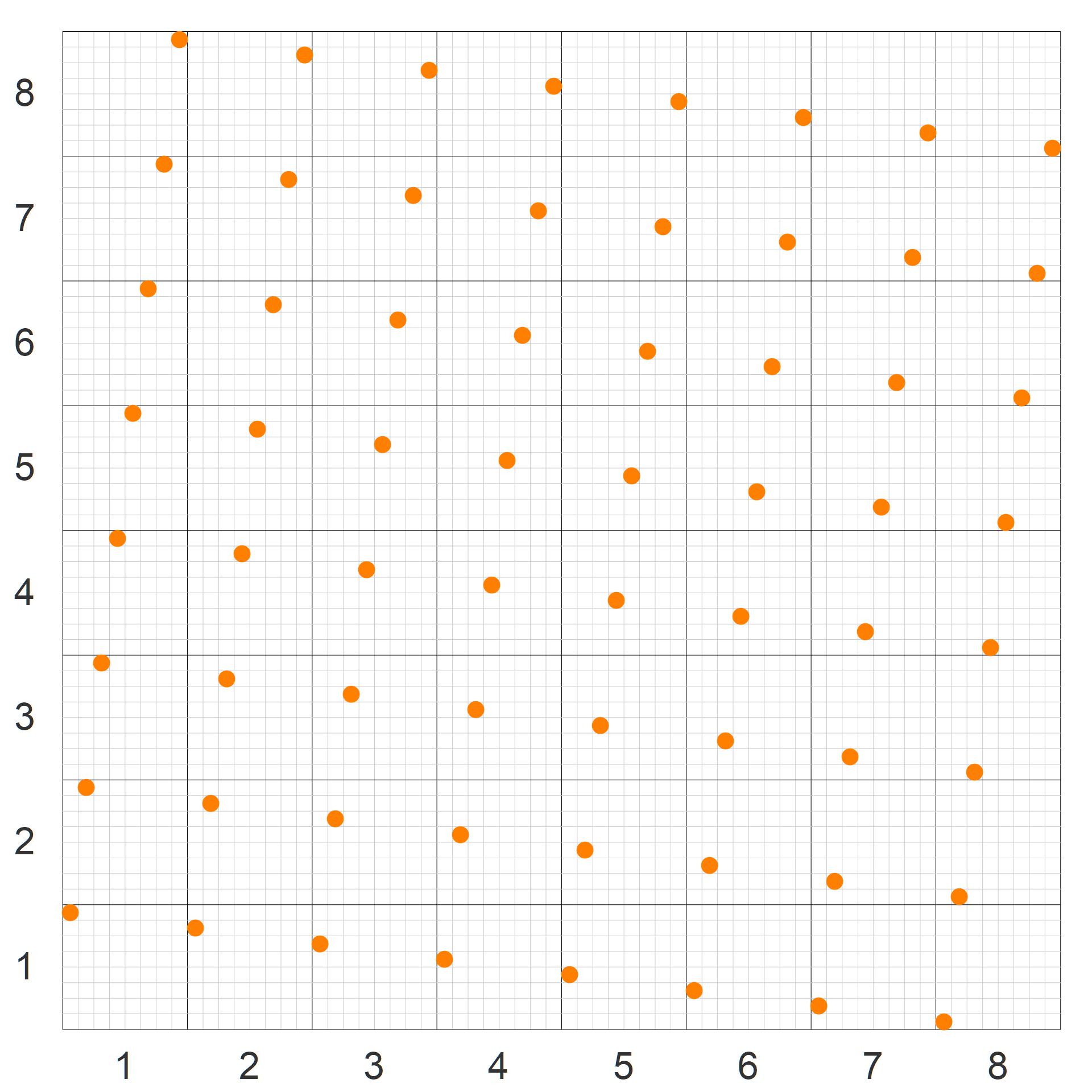
3. A new canonical layout
For even $n$, we propose an incredibly simple modification.
Despite its simplicity, of all potential permutated grid layouts that could result from correlated shuffling, this proposed one attains optimal values for $\delta_{\rm{min}}, \delta_{\rm{avg}}$ and $\delta_{\rm{max}}$.
Consider the rows and columns numbered as in figure 2a or 2b. We then simply re-arrange the rows and then the columns: first all the odd numbers in ascending order from 1 to $n$-1, and then all the even numbers in descending order starting with $n$ down to 2. For $n=8$, this is shown in figure 8.
Note you will get the equivalent results regardless of if you apply this permutation to the first variant (figure 2a) or the second variant (2b).
Also this method could be adpated to work for odd-valued $n$, but the result with not be as elegantly symmetrical nor will it be necessarily optimal.
For this proposed variant, the following holds (for $n \geq 8$):
$$ \sqrt{n^2+1}/n^2 \leq \delta_i \leq \sqrt{n^2+4}/n^2$$
For example, for $n=8$,
$$ \delta_{\rm{min}} = 8.062/64 \leq \delta_i \leq 8.246/64 = \delta_{\rm{max}}$$
Note that these values of $\delta_{\rm{min}}$ and $\delta_{\rm{max}}$ are better than any of those relating to variant 1 or variant 2.
Note also that this is an amazingly small interval, which indicates a very tight closest-neighbor distance distribution.
For this modified variant, the average distance to the closest-neighbor is now
$$\delta_{\rm{avg}} = \left(((n-4)^2 \sqrt{n^2+4} + 8(n-2) \sqrt{n^2+1} \right) /n^4 $$
Note that for all $n$, the average distance is always slightly more than $1/n$. And thus, notably better than either the first or second variant .
For example, for $n=8, \delta_{\rm{avg}} \simeq 8.108/64 $.
4. Summary
For even $n$, where a simple canonical grid layout with optimal closest neighbor characteristics are required, and aliasing is not a significant issue, then the layout proposed in section 3 (figure 1 and figure 3), is an excellent choice.
***
My name is Dr Martin Roberts, and I’m a freelance Principal Data Science consultant, who loves working at the intersection of maths and computing.
“I transform and modernize organizations through innovative data strategies solutions.”You can contact me through any of these channels.
LinkedIn: https://www.linkedin.com/in/martinroberts/
Twitter: @TechSparx https://twitter.com/TechSparx
email: Martin (at) RobertsAnalytics (dot) com
More details about me can be found here.