Bridson’s Algorithm (2007) is a very popular method to produce maximal ‘blue noise’ sample point distributions such that no two points are closer than a specified distance apart. In this brief post we show how a minor modification to this algorithm can make it up to 20x faster and allows it to produce much higher density blue noise sample point distributions.

First published: 30th November, 2019
Last updated: 6th May, 2020
Introduction.
In many applications in graphics, particularly rendering, generating samples from a blue noise sample distribution is important. Poisson-disc sampling produces points that are tightly-packed, but no closer to each other than a specified minimum distance $r_c$, resulting in a more natural looking pattern (see above figure). To create such maximal poisson disk distributions, many people use Mitchell’s best candidate, however, Bridson’s algorithm (2007) is much faster as it runs in $O(n)$ time, rather than $O(n^2)$ for Mitchell’s.
In this brief post, I show how, by changing only a few lines of its implementation code, we can make Bridson’s algorithm even more efficient. This new version is not only up to ~20x faster, but it produces higher quality point distributions, as it allows for more tightly packed and consistent point distributions.
Code for the new version can be found here.
Summary of Bridson’s algorithm.
Mike Bostock has written two very elegant explanations of how Bridson’s algorithm works. In his latest tutorial, he explains how candidate points are generated by sampling from inside an annulus of inner radius $r_c$ and outer radius $2r_c$. Furthermore, he explains how the underlying grid allows extremely fast checking of the validity of each of these candidates. His earlier visualization / tutorial, shows the time evolution of the candidates as the point distribution is constructed.
The core of the algorithm depends on uniformly selecting random points (candidates) from an annulus. This can be achieved through the standard way of first selecting a uniform point $(u,v)$ from $[0,1)^2$, and then mapping this point to the annulus. That is,
u = Math.random();
v = Math.random();
rOuter = 2 * rInner;
for (let j = 0; j < k; ++j) {
theta = 2 * Math.PI * u;
r = Math.sqrt( rInner**2 + v*(rOuter**2 - rInner**2) );
x = parent[0] + r * Math.cos(theta);
y = parent[1] + r * Math.sin(theta);
}
An improved Sampling method
However, my proposed improvement comes directly from the premise that in this very particular and surprisingly unique situation we do not need to uniformly sample from the annulus. Rather, we would prefer to select points closer to the inner radius as this is results in neighboring points closer to $r_c$.
It turns out that the following simple change to the sampler provides an extraordinary improvement to its efficiency.
(Also instead of stochastically sampling from an annulus, we are simply progressively sampling from the outside perimeter of the threshold circle.)
epsilon = 0.0000001;
seed = Math.random();
for (let j = 0; j < k; ++j) {
theta = 2 * Math.PI * (seed + 1.0*j/k);
r = rInner + epsilon;
x = parent[0] + r * Math.cos(theta);
y = parent[1] + r * Math.sin(theta);
}(I suspect that we could eliminate the need for epsilon=0.00001, if we carefully modified some of the inequality signs and/or floating point operations, throughout the code implementation.)
Observations
We can again use Bostock’s technique to visualize the the effects of this modification has on the evolution of horizon frontier of the candidates. The left image is based on the Bridson’s original algorithm. Note the wide and dispersed region of red candidates. Also note how much the grey lines are intersecting each other. Compare this to the right image which is based on the new algorithm. In this case, note the much narrower and well-defined region of red candidates. Also note how the grey lines are far more regularly structured and that none of them are intersecting!
(Don’t forget that these visualizations artificially slow down the calculations in order to make the animations nicer!)
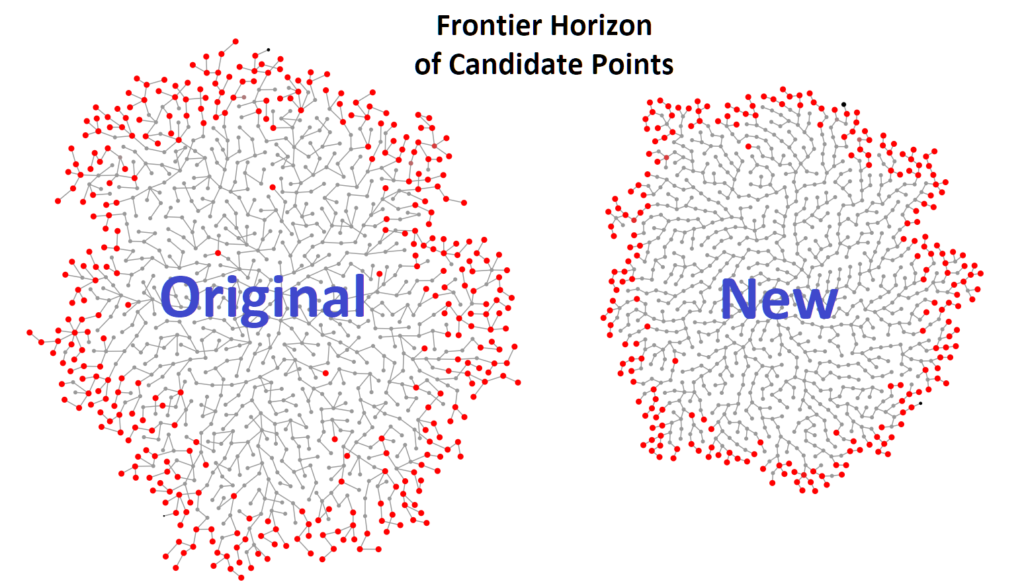
Results
Bridson’s algorithm requires setting a configuration parameter $k$, which is the maximum number of candidates to consider for each frontier point. It is generally set to a value around 30 (but sometimes up to 100).

Intuitively, increasing $k$ increases the potential point density and thus resulting in a tighter packing. The following table gives an indication on how the total number of output points varies, as this parameter $k$ varies. Also, the total number of candidates is included, as it is a useful proxy for CPU time.
(Note that these numbers are based on the default dimensions of the implementation by Jason Davies. The intent of showing these numbers is not the focus on the individual numbers per se, but rather their relative values.)
Results for Bridson’s Algorithm
\begin{array}{|r|rr|} \hline
\text{k} & \text{Candidates} &\text{Points} \\ \hline
3 & 43\text{k} & \bf{9,282} \\ \hline
10 & 140\text{k} & \bf{10,862} \\ \hline
30 & 430\text{k} & \bf{11,726} \\ \hline
100 & 1.4\text{M} &\bf{12,369} \\ \hline
300 & 4.3\text{M} & \bf{12,765} \\ \hline
1000 & 13\text{M} & \bf{13,014} \\ \hline
\end{array}
For context, all of these numbers are far less than the theoretically maximal number of 21,906 points which could be achieved if the points were distributed in a hexagonal lattice arrangement.
Below are the same data points, but this time for the modified algorithm
Results for new Modified Algorithm
\begin{array}{|r|rr|} \hline
\text{k} & \text{Candidates} & \text{Points} \\ \hline
3 & 66\text{k} & \bf{13,791} & \\ \hline
10 & 215\text{k} & \bf{15,279} \\ \hline
30 & 680\text{k} & \bf{16,758} \\ \hline
100 & 2.3\text{M} & \bf{17,542} \\ \hline
300 & 7.0\text{M} & \bf{17,797} \\ \hline
1000 & 23\text{M} & \bf{17,881} \\ \hline
\end{array}
Thus, for a given value of $k$, the new algorithm results in between 38% and 48% more points than the original value.
Said another way, using the smallest value of $k=3$ with the new algorithm will still produce more points (ie higher point density) as using the largest value of $k=1000$ with the original algorithm! Furthermore this can be achieved by testing just 66 thousand candidates rather than 13 million candidates. This is a reduction by a factor of 20!
For this new version, I recommend starting with a default setting of $k=4$, but values as high as $k=100$ are still fine.
Conclusion
I show how, by changing only a few lines of its implementation code, we can make it much more efficient. This new version is not only up to ~20x faster, but for the same value of $k$ now produces point distributions with approximately 40% higher point density.
Alternatively, one can increase the original $r_c$ by a factor of 1.2x, and then the output of both the original and the new algorithm will then have the same number of dots and the same dot distributions but the new one will run much faster.
Code for the new version can be found here.

***
My name is Dr Martin Roberts, and I’m a Principal Data Science consultant, with international experience and expertise working at the intersection of mathematics and computing.
“I transform and modernize organizations through innovative data strategies solutions.”You can contact me through any of these channels.
LinkedIn: https://www.linkedin.com/in/martinroberts/
email: Martin (at) RobertsAnalytics (dot) com
More details about me can be found here.